Keeping agent autonomy inside the lines: a technical look at governed execution
Open protocols are solving how agents reach tools. The harder problem is deciding what an agent may do, proving what it did, and stopping it mid-run. Here is how we think about that.
Gaurav Tiwari
Updated 4 min read
Key takeaways
- Protocols like MCP standardize how agents reach tools, but not what an agent is allowed to do with them.
- Governed execution needs identity, scoped access, approval gates, live control, and an audit trail recorded as the work runs.
- Treat governance as runtime architecture, not a policy document bolted on after deployment.
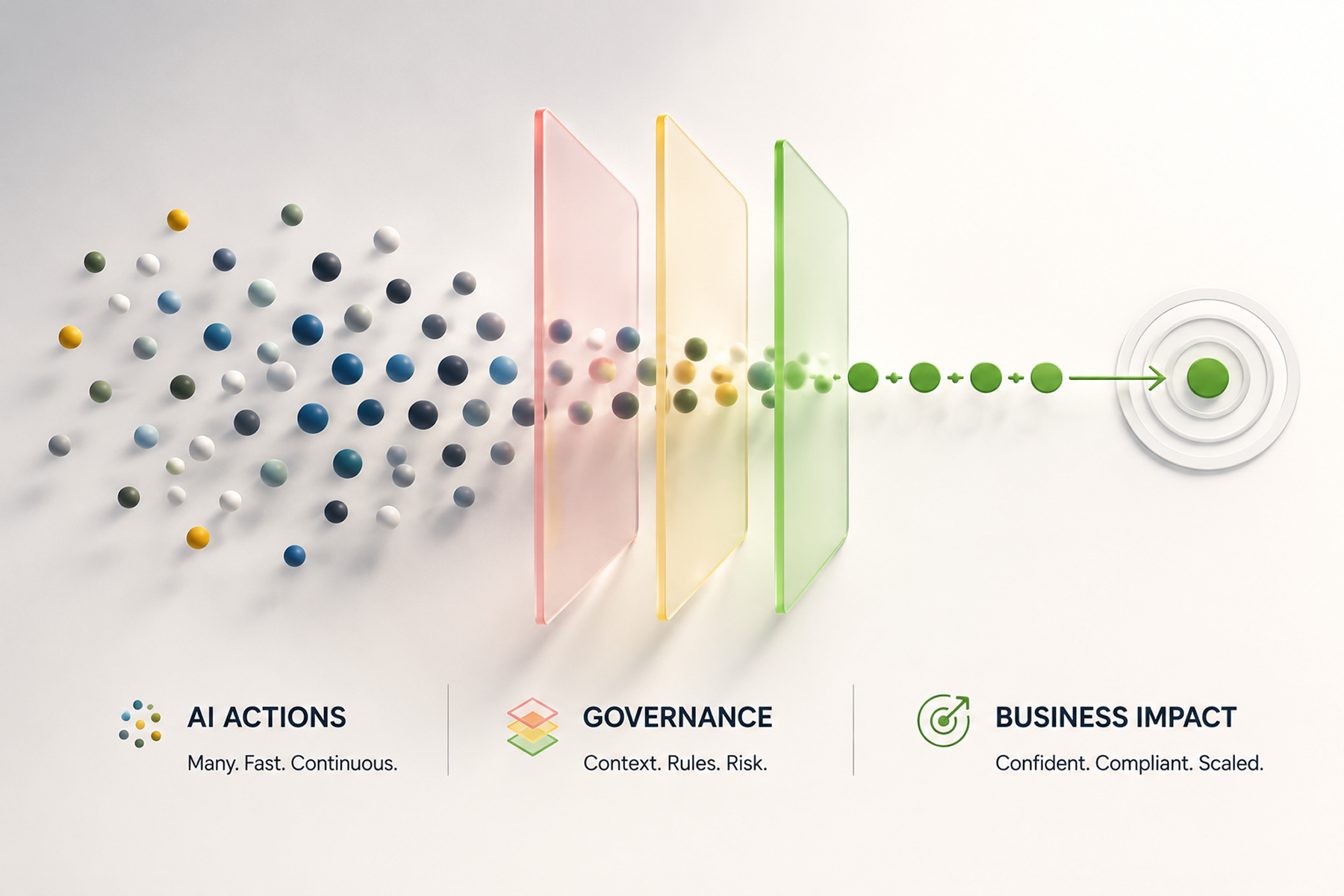
The agent conversation has quietly split into two problems. The first one — how does an agent reach the tools and data it needs — is getting solved in the open. The second one — what is this agent actually allowed to do, and how do we prove what it did — is still mostly improvised inside each company. For a small business putting an agent near real work, the second problem is the one that decides whether the project survives.
The stack is standardizing the easy half first
Connectivity is consolidating fast. The Model Context Protocol has become a common way for agents to talk to applications and data sources, and agent-to-agent coordination is following the same path. That is genuinely good. It means less bespoke glue and fewer brittle integrations.
But a protocol that lets an agent call your billing system does not decide whether it should. Gartner has been blunt about where this goes wrong: it warns that applying one uniform governance policy across every agent leads to failure, and separately predicts that over 40% of agentic AI projects will be cancelled by 2027 — largely on cost, risk, and unclear value rather than raw capability. The models can act. The question is whether the action stays inside the lines you drew.
What “governed execution” means at runtime
Governance fails when it lives in a slide deck. It works when it is part of how a run actually executes. We think about it as a small number of controls that wrap every agent, every task, on every plan.
Identity per agent
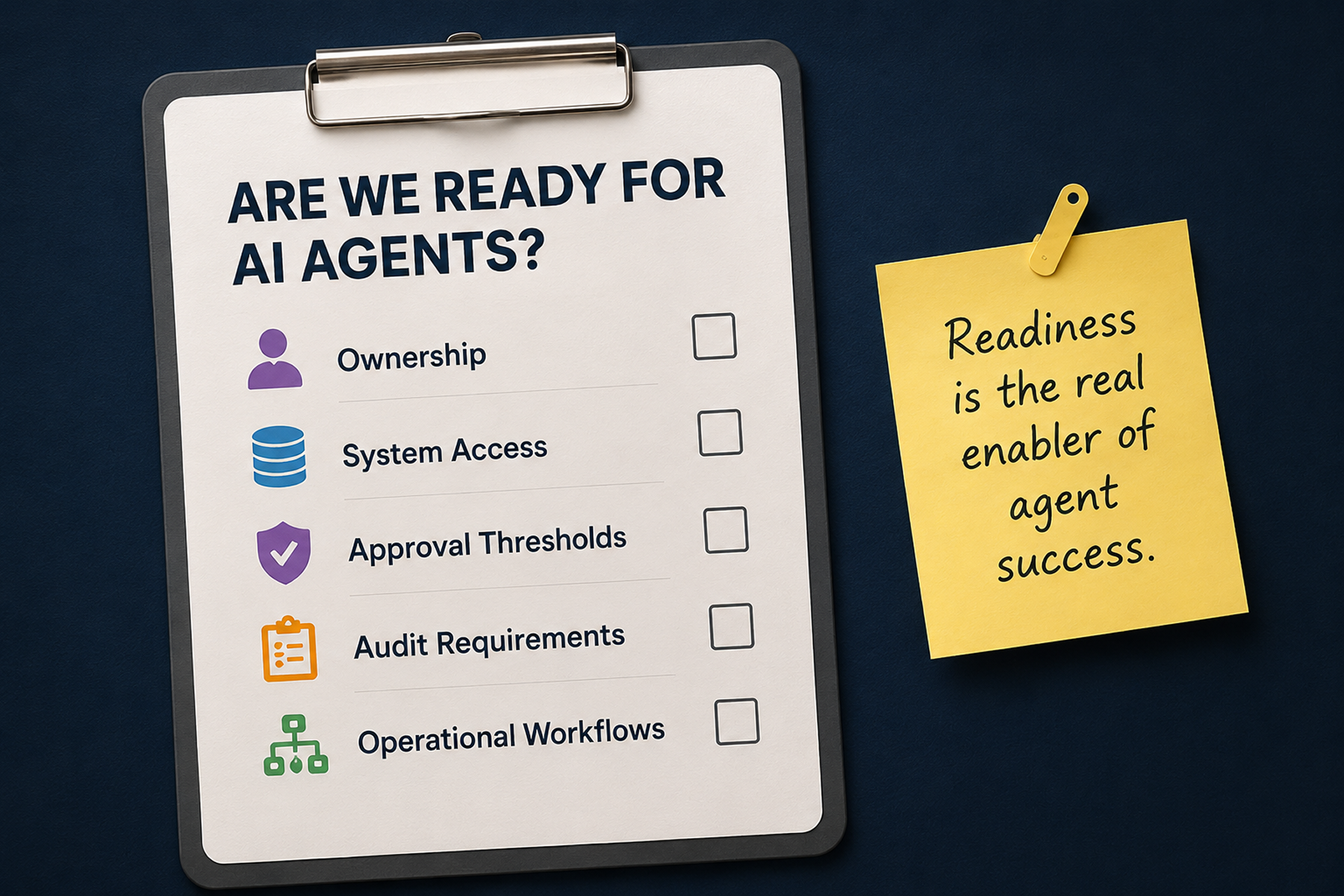
Each agent runs under its own identity with assigned ownership and accountability — not a shared service account with standing admin rights. That single decision makes everything downstream tractable: you can scope it, revoke it, and attribute every action back to it.
Scoped access, granted per task
Access is least-privilege and task-bound. An agent handling vendor renewals can reach the procurement system and the document tool it needs for that job, and nothing in finance or HR unless you explicitly allow it. Scope is enforced at the platform level, not requested politely in a prompt. Prompt-level instructions are suggestions; platform-level scope is a boundary.
Approval gates on sensitive actions
Some steps should never be fully autonomous. The agent can plan, gather evidence, and draft an action, then pause for a human decision before anything irreversible happens — sending the email, moving the money, changing the access. The agent does the legwork; a person owns the commit.
Live supervision
A governed run is observable and interruptible while it is happening. You can pause it, redirect it, or cancel it mid-task. This is the practical answer to “scope drift” — the failure mode where an agent slowly wanders outside its intended job. You do not wait for a post-incident review to find out; you watch it and stop it.
An audit trail written during the run
This is the part teams skip and regret. An audit trail reconstructed after the fact from scattered logs is a guess. A useful one is recorded as the work runs: the goal received, the plan generated, the tools and data touched, the approvals requested and granted, the actions taken, the outcome, and the cost. When something goes wrong — or when a customer, an auditor, or a regulator asks — you replay what happened instead of reverse-engineering it.
Policy controls over all of it
Security and compliance rules shape what each agent can do and what it is allowed to remember. Policy is the layer that lets the same platform behave differently for a low-risk drafting agent and a high-risk financial one — which is exactly the per-task nuance Gartner says uniform policies destroy.
Why “record as you go” is the load-bearing idea
If you only take one engineering principle from this: capture evidence at execution time, not afterward. A reconstructable trail changes the economics of trust. It turns “we think the agent did the right thing” into “here is the exact sequence, with the approval and the inputs.” That is what makes it safe to widen an agent’s scope over time, because every expansion comes with a record you can inspect.
It is also why a new category — sometimes called guardian or supervisory agents — is emerging to watch other agents for drift and policy violations in real time. The instinct is right. The cleaner version is to build that supervision into the execution layer itself, so governance is not a second agent hoping to catch the first one, but a property of how work runs.
Governance is architecture, not paperwork
The teams that will keep their agents in production are not the ones with the longest AI policy. They are the ones who made identity, scope, approval, supervision, and audit part of the runtime — so that autonomy and control are the same system, not opposing ones.
Start with one real workflow. Give the agent a narrow scope, a human checkpoint where it matters, and a trail you can replay. Then expand, with the evidence to back every step.